python编码报错
0x00 前言
使用python爬取某网站时发现,代码一直报错,起初我以为是我的headers头伪装不够好,仔细看报错信息,发现是编码的问题。然后就有了这篇记录的文章。
0x01 发现问题
爬虫报错:UnicodeEncodeError: 'gbk' codec can't encode character '\xa9' in position 51078: illegal multibyte sequence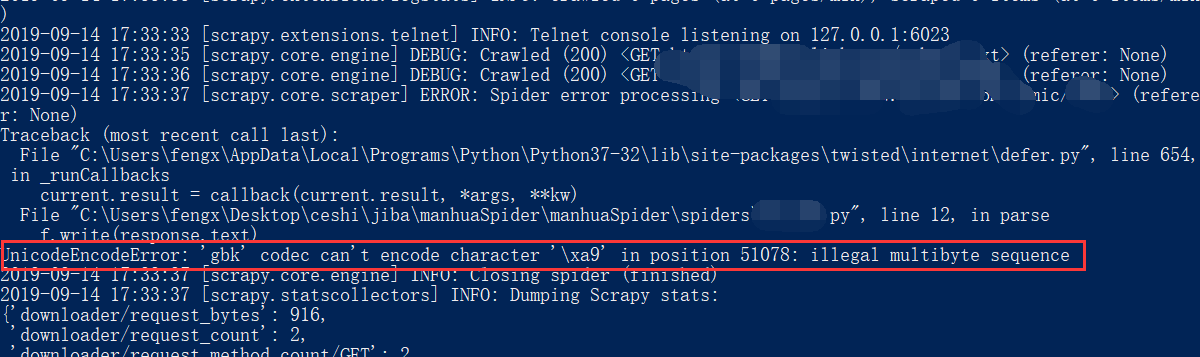
就是上图的报错,发现问题所在。
使用python写文件的时候,大部分会出现UnicodeEncodeError: 'gbk' codec can't encode character '\xa9' in position这个问题。
0x02 解决问题
解决办法:
第一种方法:或者在网络上获取的数据,先decode解码成unicode编码,然后再写入windows系统,这样就不会出现这种为题了
第二种方法:在windows下面,新文件的默认编码是gbk,这样的话,python解释器会用gbk编码去解析我们的网络数据流txt,然而txt此时已经是decode过的unicode编码,这样的话就会导致解析不了,出现上述问题。 解决的办法就是,改变目标文件的编码:
1 | f = open("xxx.html",'w',encoding='utf-8') |
这样就不会报错了。
0x03 附件问题
使用scrapy爬取的json数据,中文为unicode编码,如下图所示: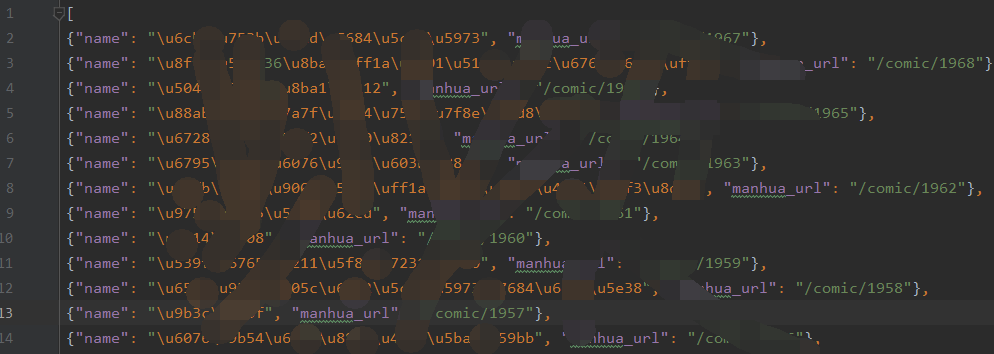
由于比较xx,所以打码处理。
解决办法:
在settings.py文件中添加一行代码:FEED_EXPORT_ENCODING = 'utf-8'
item 被转 str,默认 ensure_ascii = True,则非 ASCII 字符被转化为 unicode
再次爬取,查看数据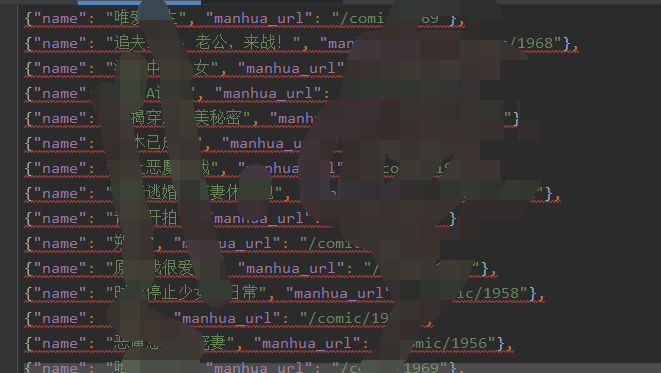
0x04 参考链接
https://doc.scrapy.org/en/latest/topics/feed-exports.html#feed-export-encoding

